I meant to blog about SQL PASS 2008, which I attended in Seattle and where I learned some good stuff, but I haven't had time. Plus there were so many blogs and tweets from it that most of what I would have said was covered. I will note that my favorite sessions were Itzik Ben-Gan's pre-conference session on Advanced T-SQL Querying and Bob Ward's talk about SQL Server memory. If you get a chance to hear either of these guys talk, jump on it - they're both extremely sharp, and good presenters to boot.
I'm posting this quick note because I had a question from one of our developers today regarding style for various joins. He wanted to know whether a condition on a secondary table in a query should go in the ON clause or the WHERE clause. This was my response:
I prefer to see conditions on the primary table in the WHERE clause, with conditions on the secondary tables in the ON clauses. This is because a condition in the WHERE clause for the secondary table when using an OUTER JOIN will effectively convert that to an INNER JOIN, making it confusing to read the query. However, putting that condition in the ON clause keeps the OUTER JOIN functioning as expected. Does that make sense?
Here’s an example with actual tables.
Notice how the first and second queries return the same thing even though the second is a left outer join, because putting the t2 condition in the WHERE clause makes it required for the whole result set instead of just the join. In the third query, the t2 condition is in the ON clause, making it only required for that join.
create table t1
(alfa int,
bravo int)
create table t2
(alfa int,
charlie int)
insert into t1
select 1, 2
union all select 2, 3
union all select 3, 4
union all select 4, 5
insert into t2
select 1, 4
union all select 2, 9
union all select 3, 16
select * from t1
inner join t2
on t1.alfa = t2.alfa
and t2.charlie = 16
where t1.alfa < 5
select * from t1
left outer join t2
on t1.alfa = t2.alfa
where t1.alfa < 5
and t2.charlie = 16
select * from t1
left outer join t2
on t1.alfa = t2.alfa
and t2.charlie = 16
where t1.alfa < 5
drop table t1, t2
Friday, December 5, 2008
Tuesday, October 28, 2008
Optimizing tempdb and log disk performance
We implemented a new SAN fairly recently: an HP EVA. In the enthusiasm to move to this new device, some tuning decisions were overlooked or made quickly, and are now being revisited. For example, all the drives allocated to database servers were created on VRAID5 (essentially equivalent to RAID 5, refer to HP's IT Resource Center for the nuances).
In general, it's a known fact that RAID 10 (aka VRAID1) outperforms RAID 5 (aka VRAID5) for write-heavy workloads, but at a higher cost per GB. I wanted to revisit the cost-benefit analysis that led us to use RAID 5, because I've always used RAID 10 for at least logs and tempdb in the past, and for all SQL data when possible.
To make sure that my analysis was relevant to our particular IO load, I planned to generate load on each type of drive using IOMeter, for which I would need to construct an appropriate workload. I recorded a Counter Log with the following counters from each drive using Windows Performance Monitor from our main OLTP server over the course of several days.
To do this, I first bucketed each reading of Avg Disk Bytes/[Read, Write] into a size category (.5K, 1K, ...64K, 128K, etc.) and chose enough categories to add up to 80% of the total in order to determine what size IOs to generate.
Then I added the averages of Disk Reads/sec and Disk Writes/sec in order to get the percentages of reads and writes against each disk, and used the average of Avg Disk Queue Length to determine how many IOs outstanding to queue up.
Finally, I ran through this whole exercise again after deciding to filter for Disk Queues > 2. I did this because I figured that the SAN probably wasn't having any trouble when disk queues were low - RAID 5 vs RAID 1 would only show a difference in latency during those times. The trouble comes when loads (for which disk queues are a proxy) are high; that's when you need maximum throughput and minimum response time.
After all this, I came up with the following characteristic workloads for our system (yours may vary substantially):
TEMPDB
Reads - 2%
- 68% 64K read size
- 32% 8K read size
Writes - 98%
- 83% 64K write size
- 17% 512B write size
600 IOs outstanding
LOGS
Reads - 36%
- 87% 128K read size
- 13% 1024K read size
Writes - 64%
- 81% 64K write size
- 19% 16K write size
4 IOs outstanding
Next I worked with our Systems Engineering group to create a VRAID5 and a VRAID1 drive of the same size and attached both to the same server. I created Access Specifications with IOMeter for each workload shown above (see image below), and then ran those Access Specifications against each drive with the requisite number of IOs outstanding.
 This yielded some fairly conclusive results. I won't post the actual throughput numbers, but here are the margins by which VRAID1 outperformed VRAID5 for each workload:
This yielded some fairly conclusive results. I won't post the actual throughput numbers, but here are the margins by which VRAID1 outperformed VRAID5 for each workload:
TEMPDB
LOGS
So according to my testing, VRAID1 is vastly superior for these types of workloads, to the point where it's probably worth the higher cost per GB. We'll see how this bears out in further testing and in real-world usage shortly...
In general, it's a known fact that RAID 10 (aka VRAID1) outperforms RAID 5 (aka VRAID5) for write-heavy workloads, but at a higher cost per GB. I wanted to revisit the cost-benefit analysis that led us to use RAID 5, because I've always used RAID 10 for at least logs and tempdb in the past, and for all SQL data when possible.
To make sure that my analysis was relevant to our particular IO load, I planned to generate load on each type of drive using IOMeter, for which I would need to construct an appropriate workload. I recorded a Counter Log with the following counters from each drive using Windows Performance Monitor from our main OLTP server over the course of several days.
- Avg Disk Bytes/Read
- Avg Disk Bytes/Write
- Avg Disk Queue Length
- Disk Reads/sec
- Disk Writes/sec
To do this, I first bucketed each reading of Avg Disk Bytes/[Read, Write] into a size category (.5K, 1K, ...64K, 128K, etc.) and chose enough categories to add up to 80% of the total in order to determine what size IOs to generate.
Then I added the averages of Disk Reads/sec and Disk Writes/sec in order to get the percentages of reads and writes against each disk, and used the average of Avg Disk Queue Length to determine how many IOs outstanding to queue up.
Finally, I ran through this whole exercise again after deciding to filter for Disk Queues > 2. I did this because I figured that the SAN probably wasn't having any trouble when disk queues were low - RAID 5 vs RAID 1 would only show a difference in latency during those times. The trouble comes when loads (for which disk queues are a proxy) are high; that's when you need maximum throughput and minimum response time.
After all this, I came up with the following characteristic workloads for our system (yours may vary substantially):
TEMPDB
Reads - 2%
- 68% 64K read size
- 32% 8K read size
Writes - 98%
- 83% 64K write size
- 17% 512B write size
600 IOs outstanding
LOGS
Reads - 36%
- 87% 128K read size
- 13% 1024K read size
Writes - 64%
- 81% 64K write size
- 19% 16K write size
4 IOs outstanding
Next I worked with our Systems Engineering group to create a VRAID5 and a VRAID1 drive of the same size and attached both to the same server. I created Access Specifications with IOMeter for each workload shown above (see image below), and then ran those Access Specifications against each drive with the requisite number of IOs outstanding.
 This yielded some fairly conclusive results. I won't post the actual throughput numbers, but here are the margins by which VRAID1 outperformed VRAID5 for each workload:
This yielded some fairly conclusive results. I won't post the actual throughput numbers, but here are the margins by which VRAID1 outperformed VRAID5 for each workload:TEMPDB
| IOPS | MB/s | Avg IO Response Time |
| 117.65% | 117.55% | 51.48% |
LOGS
| IOPS | MB/s | Avg IO Response Time |
| 80.05% | 65.63% | 39.69% |
So according to my testing, VRAID1 is vastly superior for these types of workloads, to the point where it's probably worth the higher cost per GB. We'll see how this bears out in further testing and in real-world usage shortly...
Monday, October 27, 2008
Using local disks in a cluster
With the advent of (relatively) cheap, fast Solid State Disks, DBAs everywhere are realizing that they could potentially see huge performance gains by incorporating these new disks into their database servers. This is straightforward if you've got a monolithic box: buy 2 SSDs, create a new RAID 1, move tempdb and/or logs onto it, restart SQL, shake well, and watch your IO waits go to 0! Hopefully, anyway.
However, if you've got a cluster, things are a bit trickier. The SAN vendors are still ramping up their SSD support, so it can be difficult to get an SSD into a shared storage enclosure unless you roll your own. Especially if you pick up one of the most promising new disks, the FusionIO ioDrive. This disk gets attached to a PCIe bus directly rather than a SAS or SATA backplane, so it can't be put into most commercially available shared storage devices (SANs, NASs, etc.).
Even so, we were sufficiently impressed by the IO stats on this disk to pick up a couple of them, but we still wanted to put them in our production cluster. We can't use them for shared data, obviously, as the data wouldn't persist between machines. But in theory they could be perfect for tempdb, which gets wiped out on each restart and so only needs to see the same path on each machine. I figured there was probably a way to get Microsoft Cluster Services to see the local SSDs on each machine as the same disk.
To test this theory, we (I and coworker Doug H.) took a pair of virtual machines, added drives to simulate a standard local disk, shared SAN storage, and the new SSD, built them into a cluster, and installed SQL Server 2005 on the R: drive.
Disk 0 (C:) - local - boot disk
Disk 1 (Q:) - shared - quorum
Disk 2 (R:) - shared - SQL data
Disk 3 (D:) - local - simulated SSD
When the VMs were initially configured, the fake SSDs were created on the same SCSI bus as the boot disk. The cluster administrator quickly informed us that this would not fly - disks on the same bus as the boot disk cannot be used as shared resources. So we moved the D: drives to a new bus, separate from both the C: (simulated backplane) and Q:/R: (simulated SAN) drives.
The next step was to add the D: drive to the cluster. I assumed this wouldn't work without some hacking, but I decided to try a "baseline" attempt without any modifications. The Cluster Admin New Resource wizard allowed me to add the D: drive on one of the nodes, but it wouldn't come online. So much for the baseline attempt.
I knew that Windows 2003 (though maybe not 2008) clustering relies on disk signatures to identify disks for cluster operations, so I decided to synchronize the signatures of the two fake SSDs. To this end, I found a utility - MBRWizard - that would let me manually set the signature of an MBR disk.
Using this utility, I found the signature of the D: drive on machine #1:
mbrwiz /Disk=3 /Signature
and then overwrote the signature of the D: drive on machine #2:
mbrwiz /Disk=3 /Signature=xxxxxxxx
Then I added the disk as a cluster resource again, and brought it online. Success! Failover worked, too, so I failed the SQL Server group (Group 0 in the image below) back and forth between nodes and created a Data directory on each D: drive.

The next step was to make sure it worked with SQL Server. I took SQL offline, added Disk D: as a dependency, and brought it back up. Then I altered tempdb's location to use the D: drive after a restart.
alter database tempdb
modify file (NAME=tempdev, FILENAME = 'D:\Data\tempdb.mdf')
GO
alter database tempdb
modify file (NAME=templog, FILENAME = 'D:\Data\templog.ldf')
GO
Finally I took SQL offline and brought it back up, with fingers crossed. And it worked! Failover worked too.
So my proof of concept for using a local SSD in a cluster (for tempdb only!) was successful. Stay tuned to see if it works in the real world.
However, if you've got a cluster, things are a bit trickier. The SAN vendors are still ramping up their SSD support, so it can be difficult to get an SSD into a shared storage enclosure unless you roll your own. Especially if you pick up one of the most promising new disks, the FusionIO ioDrive. This disk gets attached to a PCIe bus directly rather than a SAS or SATA backplane, so it can't be put into most commercially available shared storage devices (SANs, NASs, etc.).
Even so, we were sufficiently impressed by the IO stats on this disk to pick up a couple of them, but we still wanted to put them in our production cluster. We can't use them for shared data, obviously, as the data wouldn't persist between machines. But in theory they could be perfect for tempdb, which gets wiped out on each restart and so only needs to see the same path on each machine. I figured there was probably a way to get Microsoft Cluster Services to see the local SSDs on each machine as the same disk.
To test this theory, we (I and coworker Doug H.) took a pair of virtual machines, added drives to simulate a standard local disk, shared SAN storage, and the new SSD, built them into a cluster, and installed SQL Server 2005 on the R: drive.
Disk 0 (C:) - local - boot disk
Disk 1 (Q:) - shared - quorum
Disk 2 (R:) - shared - SQL data
Disk 3 (D:) - local - simulated SSD
When the VMs were initially configured, the fake SSDs were created on the same SCSI bus as the boot disk. The cluster administrator quickly informed us that this would not fly - disks on the same bus as the boot disk cannot be used as shared resources. So we moved the D: drives to a new bus, separate from both the C: (simulated backplane) and Q:/R: (simulated SAN) drives.
The next step was to add the D: drive to the cluster. I assumed this wouldn't work without some hacking, but I decided to try a "baseline" attempt without any modifications. The Cluster Admin New Resource wizard allowed me to add the D: drive on one of the nodes, but it wouldn't come online. So much for the baseline attempt.
I knew that Windows 2003 (though maybe not 2008) clustering relies on disk signatures to identify disks for cluster operations, so I decided to synchronize the signatures of the two fake SSDs. To this end, I found a utility - MBRWizard - that would let me manually set the signature of an MBR disk.
Using this utility, I found the signature of the D: drive on machine #1:
mbrwiz /Disk=3 /Signature
and then overwrote the signature of the D: drive on machine #2:
mbrwiz /Disk=3 /Signature=xxxxxxxx
Then I added the disk as a cluster resource again, and brought it online. Success! Failover worked, too, so I failed the SQL Server group (Group 0 in the image below) back and forth between nodes and created a Data directory on each D: drive.

The next step was to make sure it worked with SQL Server. I took SQL offline, added Disk D: as a dependency, and brought it back up. Then I altered tempdb's location to use the D: drive after a restart.
alter database tempdb
modify file (NAME=tempdev, FILENAME = 'D:\Data\tempdb.mdf')
GO
alter database tempdb
modify file (NAME=templog, FILENAME = 'D:\Data\templog.ldf')
GO
Finally I took SQL offline and brought it back up, with fingers crossed. And it worked! Failover worked too.
So my proof of concept for using a local SSD in a cluster (for tempdb only!) was successful. Stay tuned to see if it works in the real world.
Friday, October 3, 2008
Running a Buildbot buildslave as a Windows service
Buildbot is an open source continuous integration system written in Python. We use it to automate the builds on one of the projects I work on, and in general, it's cool. Pretty easy to set up (just make sure you look at every setting in the config file), comes with its own simple but handy web interface, and allows quick configuration of multiple "builders" and "buildslaves."
However, like most open source projects, it's written for and by *nix users and doesn't have full Windows support. Fortunately, Mark Hammond (of win32api fame) deigned to write the buildbot_service.py file, which allows installation of the Buildbot buildmaster as a service.
But despite this, there's no out-of-the-box way to run a buildslave as a service. There are a few other hardy souls out there who have figured out various methods for accomplishing this, and I am indebted to their guides as helpful starting points. But I didn't like all the registry hacking and configuration steps, so I went another way. Hammond's buildbot_service.py scares me, but I gleaned enough from it to put together my own buildslave_service.py.
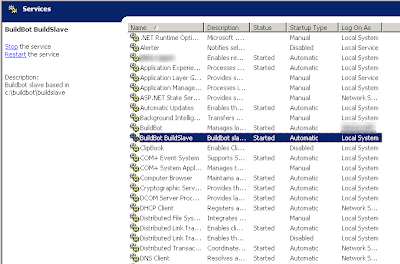 It's not terribly full-featured, and it requires reinstallation if any settings are changed, but it's compact, effective, and easy to install.
It's not terribly full-featured, and it requires reinstallation if any settings are changed, but it's compact, effective, and easy to install.
Steps:
1) Copy code below, correct spacing that Blogger's HTML window stripped out, change paths as appropriate, save as buildslave_service.py.
2) Install the service (w/ optional parameter for automatic startup if you want):
python buildslave_service.py install [--startup=auto]
3) Start the service:
net start Buildbot_Buildslave
(or use the Services mmc snap-in)
And that's it! Easier than all the registry mess and downloading Win2003 resource packs, no?
""" buildslave_service.py
Original Author: Ira Pfeifer
Email: ipfeifer -dot- tech -at- gmail
"""
import sys
import os
import subprocess
import win32serviceutil
import win32service
import win32event
import win32api
import time
from buildbot.scripts import runner
from buildbot.scripts.startup import start
# change paths as appropriate
slavepath = "c:\\buildbot\\buildslave"
homepath = "\\"
os.environ['HOMEDRIVE'] = "C:"
os.environ['HOMEPATH'] = homepath
os.environ['PATH'] = ";".join([
r"C:\Python25"
,r"C:\Python25\Scripts"
])
class BuildSlaveService(win32serviceutil.ServiceFramework):
_svc_name_ = "BuildBot_BuildSlave"
_svc_display_name_ = "BuildBot BuildSlave"
_svc_description_ = "Buildbot slave based in " + slavepath
def __init__(self, args):
win32serviceutil.ServiceFramework.__init__(self, args)
self.stop_event = win32event.CreateEvent(None, 0, 0, None)
def SvcDoRun(self):
# The service starts a subprocess that will run the actual buildbot
# so that it can be stopped by simply killing off the subprocess.
self.child = subprocess.Popen(["python",
__file__,
"start"])
isAlive = True
while isAlive:
time.sleep(10)
def SvcStop(self):
self.ReportServiceStatus(win32service.SERVICE_STOP_PENDING)
handle = win32api.OpenProcess(1,0,self.child.pid)
# returns exit code - wrap w/ error handling?
win32api.TerminateProcess(handle, 0)
win32api.CloseHandle(handle)
isAlive = False
self.ReportServiceStatus(win32service.SERVICE_STOP_PENDING)
win32.SetEvent(self.hWaitStop)
SvcShutdown = SvcStop
def start_buildslave():
config = runner.Options()
config.parseOptions(['start',slavepath])
so = config.subOptions
start(so)
if __name__ == '__main__':
if len(sys.argv) > 1 and sys.argv[1] == "start":
start_buildslave()
else:
win32serviceutil.HandleCommandLine(BuildSlaveService)
However, like most open source projects, it's written for and by *nix users and doesn't have full Windows support. Fortunately, Mark Hammond (of win32api fame) deigned to write the buildbot_service.py file, which allows installation of the Buildbot buildmaster as a service.
But despite this, there's no out-of-the-box way to run a buildslave as a service. There are a few other hardy souls out there who have figured out various methods for accomplishing this, and I am indebted to their guides as helpful starting points. But I didn't like all the registry hacking and configuration steps, so I went another way. Hammond's buildbot_service.py scares me, but I gleaned enough from it to put together my own buildslave_service.py.
 It's not terribly full-featured, and it requires reinstallation if any settings are changed, but it's compact, effective, and easy to install.
It's not terribly full-featured, and it requires reinstallation if any settings are changed, but it's compact, effective, and easy to install.Steps:
1) Copy code below, correct spacing that Blogger's HTML window stripped out, change paths as appropriate, save as buildslave_service.py.
2) Install the service (w/ optional parameter for automatic startup if you want):
python buildslave_service.py install [--startup=auto]
3) Start the service:
net start Buildbot_Buildslave
(or use the Services mmc snap-in)
And that's it! Easier than all the registry mess and downloading Win2003 resource packs, no?
""" buildslave_service.py
Original Author: Ira Pfeifer
Email: ipfeifer -dot- tech -at- gmail
"""
import sys
import os
import subprocess
import win32serviceutil
import win32service
import win32event
import win32api
import time
from buildbot.scripts import runner
from buildbot.scripts.startup import start
# change paths as appropriate
slavepath = "c:\\buildbot\\buildslave"
homepath = "\\"
os.environ['HOMEDRIVE'] = "C:"
os.environ['HOMEPATH'] = homepath
os.environ['PATH'] = ";".join([
r"C:\Python25"
,r"C:\Python25\Scripts"
])
class BuildSlaveService(win32serviceutil.ServiceFramework):
_svc_name_ = "BuildBot_BuildSlave"
_svc_display_name_ = "BuildBot BuildSlave"
_svc_description_ = "Buildbot slave based in " + slavepath
def __init__(self, args):
win32serviceutil.ServiceFramework.__init__(self, args)
self.stop_event = win32event.CreateEvent(None, 0, 0, None)
def SvcDoRun(self):
# The service starts a subprocess that will run the actual buildbot
# so that it can be stopped by simply killing off the subprocess.
self.child = subprocess.Popen(["python",
__file__,
"start"])
isAlive = True
while isAlive:
time.sleep(10)
def SvcStop(self):
self.ReportServiceStatus(win32service.SERVICE_STOP_PENDING)
handle = win32api.OpenProcess(1,0,self.child.pid)
# returns exit code - wrap w/ error handling?
win32api.TerminateProcess(handle, 0)
win32api.CloseHandle(handle)
isAlive = False
self.ReportServiceStatus(win32service.SERVICE_STOP_PENDING)
win32.SetEvent(self.hWaitStop)
SvcShutdown = SvcStop
def start_buildslave():
config = runner.Options()
config.parseOptions(['start',slavepath])
so = config.subOptions
start(so)
if __name__ == '__main__':
if len(sys.argv) > 1 and sys.argv[1] == "start":
start_buildslave()
else:
win32serviceutil.HandleCommandLine(BuildSlaveService)
Sunday, September 28, 2008
CPU Affinity Masking plus High CPU = Login Timeouts
Recently we saw an alarming issue with one of our database servers. Under heavy but not prohibitive load (60-80% CPU), it stopped accepting new connections intermittently. Obviously this is bad for any server, especially one that handles thousands of client connections simultaneously.
Some of the hard drives were under heavy load, especially tempdb, but another anomaly was a long-running query using many linked server connections (11!) that had been killed but was stuck in rollback several hours later. It was consuming near 100% of the cycles on one CPU core. We tried a variety of the usual DBA tricks to get rid of this spid, but nothing worked. It wasn't clear to us how this could cause the server to stop accepting connections, however.
Another oddity was the appearance in the System logs of messages like this:
The time stamp counter of CPU on scheduler id 2 is not synchronized with other CPUs.
I asked our Systems guys about this, and they said that this had been noticed a few months ago and a workaround had been put in place as per KB 931279 - the CPU affinity mask had been set in SQL Server.
Hmm.
This happened again a week later, minus the spid stuck in rollback, but with one CPU slammed at 100% again. We had engaged Microsoft PSS to assist with the problem, but so far all they had told us was that we had tempdb IO issues, which we knew. (DVNation, please finish the Windows drivers for your IODrives so we can use them for tempdb!)
So here's my theory, cooked up with one of the other DBAs: the login issues are being caused by the combination of affinity masking and one CPU at 100%. This could happen because schedulers are affinitized by the mask to a single CPU, making them unable to hop CPUs when one is under heavy load. User logins round-robin between schedulers, so if a scheduler is stuck to a single CPU and that CPU is not making enough cycles available to log someone in, eventually the login will timeout and fail.
Plausible? Anyone else seen this kind of issue?
UPDATE:
I was right. After removing the affinity masking, we no longer saw login timeouts, even when the server was near 100% CPU load. Be careful with those affinity masks.
Some of the hard drives were under heavy load, especially tempdb, but another anomaly was a long-running query using many linked server connections (11!) that had been killed but was stuck in rollback several hours later. It was consuming near 100% of the cycles on one CPU core. We tried a variety of the usual DBA tricks to get rid of this spid, but nothing worked. It wasn't clear to us how this could cause the server to stop accepting connections, however.
Another oddity was the appearance in the System logs of messages like this:
The time stamp counter of CPU on scheduler id 2 is not synchronized with other CPUs.
I asked our Systems guys about this, and they said that this had been noticed a few months ago and a workaround had been put in place as per KB 931279 - the CPU affinity mask had been set in SQL Server.
Hmm.
This happened again a week later, minus the spid stuck in rollback, but with one CPU slammed at 100% again. We had engaged Microsoft PSS to assist with the problem, but so far all they had told us was that we had tempdb IO issues, which we knew. (DVNation, please finish the Windows drivers for your IODrives so we can use them for tempdb!)
So here's my theory, cooked up with one of the other DBAs: the login issues are being caused by the combination of affinity masking and one CPU at 100%. This could happen because schedulers are affinitized by the mask to a single CPU, making them unable to hop CPUs when one is under heavy load. User logins round-robin between schedulers, so if a scheduler is stuck to a single CPU and that CPU is not making enough cycles available to log someone in, eventually the login will timeout and fail.
Plausible? Anyone else seen this kind of issue?
UPDATE:
I was right. After removing the affinity masking, we no longer saw login timeouts, even when the server was near 100% CPU load. Be careful with those affinity masks.
Monday, September 22, 2008
psexec Permission denied error
In the course of my DBA and software dev tasks, I make extensive use of Mark Russinovich's excellent PSTools. Today I ran across an odd error while running a remote command using psexec. Filenames have been changed, obviously, but here's the gist of it:
> psexec \\remotemachine python \\fileserver\script.py param1 param2
python: can't open file '\\fileserver\script.py': [Errno 13] Permission denied
So it was obviously opening python, which I double-checked by running with the -i option and checking the remote machine's desktop using VNC Viewer. The python shell was opening successfully, but it couldn't access the file server. Executing the script directly from the remote machine's command line worked fine.
Then I realized that this was the same issue that one gets from too (two? ;) many linked server hops using integrated authentication - it's a two-hop Kerberos problem. Google that if you don't know what I'm talking about. Fortunately, psexec offers the option of passing a username and password, and as soon as I added those options, my command executed successfully.
> psexec \\remotemachine python \\fileserver\script.py param1 param2
python: can't open file '\\fileserver\script.py': [Errno 13] Permission denied
So it was obviously opening python, which I double-checked by running with the -i option and checking the remote machine's desktop using VNC Viewer. The python shell was opening successfully, but it couldn't access the file server. Executing the script directly from the remote machine's command line worked fine.
Then I realized that this was the same issue that one gets from too (two? ;) many linked server hops using integrated authentication - it's a two-hop Kerberos problem. Google that if you don't know what I'm talking about. Fortunately, psexec offers the option of passing a username and password, and as soon as I added those options, my command executed successfully.
Tuesday, September 16, 2008
Tuesday, September 9, 2008
SSIS Data Flow Task Error caused by too many Data Flow tasks
I just threw together a very basic SQL 2005 SSIS package, the main component of which is a Data Flow task with 25 sub-flows. The flows are very simple, just direct transfers of a table on one server to the same table name on another server. As an aside, it took WAY too long to create this package - for each little flow, I had to select the source connection, wait for it to populate the table drop-down, then scroll through that drop-down through hundreds of tables to find the one I wanted, then do it again for the destination. This could be better in a number of ways:
Anyway, when attempting to execute the package, I was consistently getting a failure from one flow with this error:
TCP Provider: An existing connection was forcibly closed by the remote host
This didn't make much sense to me, as it worked fine when run by itself. I found this article and added that registry key, but it did not fix the problem (although it did seem to increase throughput).
Then I noticed that the two largest flows in the Data Flow task (on the order of millions of rows) were executing at the time when the problem task was throwing an error. I thought SSIS would be able to handle the sequencing of parallel tasks, but I decided to enforce my own execution order by placing the two large flows in a separate Data Flow task.
 Voila. Works fine. So if you're having issues with an overpopulated Data Flow task throwing that TCP error, one simple workaround is to manually sequence/reduce the parallel execution of the tasks.
Voila. Works fine. So if you're having issues with an overpopulated Data Flow task throwing that TCP error, one simple workaround is to manually sequence/reduce the parallel execution of the tasks.
- Allow typing in the table field. It would have been much quicker to allow me to type or copy and paste the table name rather than waiting for the drop-down and then scrolling through it. 50 times.
- Improve copy and paste of flow tasks. If I could have constructed one and duplicated it 25 times, it would have been much quicker, but when I attempted that, I got strange warnings about field truncation that were cleared up only by deleting the source and re-creating it.
- Create a wizard that facilitates auto-generating this kind of simple package better than the Transfer Objects wizard.
Anyway, when attempting to execute the package, I was consistently getting a failure from one flow with this error:
TCP Provider: An existing connection was forcibly closed by the remote host
This didn't make much sense to me, as it worked fine when run by itself. I found this article and added that registry key, but it did not fix the problem (although it did seem to increase throughput).
Then I noticed that the two largest flows in the Data Flow task (on the order of millions of rows) were executing at the time when the problem task was throwing an error. I thought SSIS would be able to handle the sequencing of parallel tasks, but I decided to enforce my own execution order by placing the two large flows in a separate Data Flow task.
 Voila. Works fine. So if you're having issues with an overpopulated Data Flow task throwing that TCP error, one simple workaround is to manually sequence/reduce the parallel execution of the tasks.
Voila. Works fine. So if you're having issues with an overpopulated Data Flow task throwing that TCP error, one simple workaround is to manually sequence/reduce the parallel execution of the tasks.
Monday, September 8, 2008
Programming Languages I know
To pick up the latest blog mini-meme (courtesy of Corey Goldberg), here's The List of programming languages I have learned:
1. AppleScript
2. C
3. Java
4. Lisp (Scheme)
5. C++
6. JavaScript
7. ANSI SQL*
8. PHP
9. T-SQL
10. VBScript
11. C#
12. Python
Kind of a strange order, no? Mostly driven by expediency, except Scheme and C++, which I learned in college.
UPDATE: Dan points out that ANSI SQL is not Turing complete and should be asterisked, so I guess I'm down to 11.5. Let's see your monster list, Dan - mcfunley.com has been pretty quiet lately.
1. AppleScript
2. C
3. Java
4. Lisp (Scheme)
5. C++
6. JavaScript
7. ANSI SQL*
8. PHP
9. T-SQL
10. VBScript
11. C#
12. Python
Kind of a strange order, no? Mostly driven by expediency, except Scheme and C++, which I learned in college.
UPDATE: Dan points out that ANSI SQL is not Turing complete and should be asterisked, so I guess I'm down to 11.5. Let's see your monster list, Dan - mcfunley.com has been pretty quiet lately.
Friday, September 5, 2008
DTS Editing doesn't work in SQL 2008?
I've been running the SQL 2008 RTM for a few weeks now, and generally it works fine. But today I needed to open an ancient DTS package (it's not from my team, all our stuff is SSIS), and couldn't do it. First it told me I needed the SQL 2005 Backwards Compatibility components. "That's odd," I thought, "I could have sworn I installed all of that when I ran the SQL 2008 setup. And why is it asking for the 2005 components?"
It appears that Microsoft has simply updated the 2005 BC component install to work with 2008. Fine. I installed that, and tried to open the package again. No dice.

So I went to find those components. Found the package, installed it... to no effect whatsoever! I still get the same message! Note to Microsoft: if you don't want me to edit DTS packages in 2008 and have deprecated that functionality entirely, fine. Just TELL ME instead of popping up worthless error messages whose instructions I follow to no avail.
It appears that Microsoft has simply updated the 2005 BC component install to work with 2008. Fine. I installed that, and tried to open the package again. No dice.

So I went to find those components. Found the package, installed it... to no effect whatsoever! I still get the same message! Note to Microsoft: if you don't want me to edit DTS packages in 2008 and have deprecated that functionality entirely, fine. Just TELL ME instead of popping up worthless error messages whose instructions I follow to no avail.
Tuesday, August 26, 2008
Float comparison tolerance
Had the age-old problem with significant figures when comparing floats in Python today, and came up with this little function to deal with it. It ensures that the two values are equal down to 10 significant figures, no matter at what scale they start. This is as opposed to the conventional test, which checks at a fixed scale (e.g. return abs(a - b) < 1e-10).
def equal(a, b):
return abs(a - b) <= abs(a - b)/10000000000
Testing:
a = .0000000000000000837
b = .00000000000000004315
c = a + 100
d = b + 100
equal(a,b)
False
equal(b,a)
False
equal(c,d)
True
equal(d,c)
True
equal(1,1)
True
(Of course, we wound up defining a hard limit, 1e-10, and not using my function, but I still thought it was clever.)
UPDATE: Yes, I recognize that this is hardly a new problem or solution, but it's MY BLOG and I mostly use it as a memory aid anyway - outside readers are incidental (which is a good thing, given my Google Analytics stats).
def equal(a, b):
return abs(a - b) <= abs(a - b)/10000000000
Testing:
a = .0000000000000000837
b = .00000000000000004315
c = a + 100
d = b + 100
equal(a,b)
False
equal(b,a)
False
equal(c,d)
True
equal(d,c)
True
equal(1,1)
True
(Of course, we wound up defining a hard limit, 1e-10, and not using my function, but I still thought it was clever.)
UPDATE: Yes, I recognize that this is hardly a new problem or solution, but it's MY BLOG and I mostly use it as a memory aid anyway - outside readers are incidental (which is a good thing, given my Google Analytics stats).
Friday, July 18, 2008
Automated linked server test
Got a big production event scheduled, so I wrote this quick automated test to be incorporated into the post-event testing. I'll probably improve on it incrementally as I notice shortcomings, but at the moment it's just a basic test of data access via all linked servers set up on a machine.
/*** Linked Server Test ***/
declare @linked table (name sysname, done bit, retval int)
declare @srvr sysname
declare @sql varchar(255)
declare @retval int
insert into @linked select name, 0 as done, NULL as retval from sys.servers
while exists (select 1 from @linked where done = 0)
begin
select top 1 @srvr = name from @linked where done = 0
begin try
exec @retval = sp_testlinkedserver @srvr
end try
begin catch
set @retval = sign(@@error)
end catch
exec(@sql)
update @linked set done = 1, retval = @retval where name = @srvr
end
select * from @linked
/*** Linked Server Test ***/
declare @linked table (name sysname, done bit, retval int)
declare @srvr sysname
declare @sql varchar(255)
declare @retval int
insert into @linked select name, 0 as done, NULL as retval from sys.servers
while exists (select 1 from @linked where done = 0)
begin
select top 1 @srvr = name from @linked where done = 0
begin try
exec @retval = sp_testlinkedserver @srvr
end try
begin catch
set @retval = sign(@@error)
end catch
exec(@sql)
update @linked set done = 1, retval = @retval where name = @srvr
end
select * from @linked
Monday, July 14, 2008
pyodbc returns an int instead of rows in a cursor
Just a quick note about pyodbc: if you're getting a TypeError from a pyodbc cursor because it's an int instead of a rowset, it's probably because the proc or query being called is returning extra info or messages. Try turning off anything that's returning extraneous info, like ANSI_WARNINGS.
Tuesday, June 17, 2008
SQL 2008 installation problems
Several of us at my office had issues installing SQL 2008 RC0 - the installer kept failing the "Restart computer" check.
So I started digging through the registry to find the culprit flag... when this forum post turned up and pointed me to exactly the right place.
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3492057&SiteID=1
Turns out our virus scanning software always posts a pending file rename, which SQL setup interprets as the computer needing a reboot. I cleared these values and the installer ran fine.
UPDATE: Had the same problem with SQL 2008 RTM. Fix works for that too, and probably for many other installers that refuse to start due to a pending file operation.
So I started digging through the registry to find the culprit flag... when this forum post turned up and pointed me to exactly the right place.
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3492057&SiteID=1
Turns out our virus scanning software always posts a pending file rename, which SQL setup interprets as the computer needing a reboot. I cleared these values and the installer ran fine.
UPDATE: Had the same problem with SQL 2008 RTM. Fix works for that too, and probably for many other installers that refuse to start due to a pending file operation.
Tuesday, June 10, 2008
Returning rows from a stored procedure with pyodbc, pt 2
Pyodbc really doesn't like extraneous information to be returned with its (ONE AND ONLY ONE!) result set from a stored procedure.
In my latest fight with pyodbc, I had a stored proc returning a rowset with a few thousand rows. This worked fine most of the time, except in a few cases with certain input parameters. In those cases, the cursor returned by execute() would contain an int, so any cursor method I called on it would break.
At first I thought I might have hit some kind of row size limit or rowcount limit, but realized the result set wasn't big enough for that to be the case. The proc wasn't throwing off any errors when run in SQL Management Studio with the same input parameters, so that wasn't the problem.
Then I noticed that it was returning a single warning message in the Messages tab.
Warning: Null value is eliminated by an aggregate or other SET operation.
This is a fairly common warning in SQL land, so I hadn't paid any attention to it. But it is possible to suppress, using the following statement:
SET ANSI_WARNINGS OFF
Sure enough, this did the trick. The moral of this story (just like last time) is that pyodbc wants a single rowset and that's it; returning any data in any of the alternate ODBC channels seems to break it, or at least, not yield the cursor in the result set that I expected.
In my latest fight with pyodbc, I had a stored proc returning a rowset with a few thousand rows. This worked fine most of the time, except in a few cases with certain input parameters. In those cases, the cursor returned by execute() would contain an int, so any cursor method I called on it would break.
At first I thought I might have hit some kind of row size limit or rowcount limit, but realized the result set wasn't big enough for that to be the case. The proc wasn't throwing off any errors when run in SQL Management Studio with the same input parameters, so that wasn't the problem.
Then I noticed that it was returning a single warning message in the Messages tab.
Warning: Null value is eliminated by an aggregate or other SET operation.
This is a fairly common warning in SQL land, so I hadn't paid any attention to it. But it is possible to suppress, using the following statement:
SET ANSI_WARNINGS OFF
Sure enough, this did the trick. The moral of this story (just like last time) is that pyodbc wants a single rowset and that's it; returning any data in any of the alternate ODBC channels seems to break it, or at least, not yield the cursor in the result set that I expected.
Saturday, June 7, 2008
Speeding up Vista User Access Control (UAC)
My HP laptop (tx1210) runs Vista Home Premium, and I'm constantly performing actions on it that pop up the User Access Control window. I don't have a problem with this in and of itself, as I've read Microsoft's side of the argument and I'm willing to give them the benefit of the doubt and assume that this does actually provide some additional security.
That said, it's slow as hell.
The UAC popup isn't bad on my monster desktop, which has a top-end Core 2 Duo, 4 GB of RAM, and a decent video card, but it takes FOREVER on my laptop - probably 3-5 seconds to black out the screen and pop up the prompt, and another 3-5 to black out the screen again and return me to what I was doing. This is unacceptable in 2008.
After reading a few unhelpful posts directing me to disable UAC completely, I found one that mentioned that it wasn't as slow with Aero (the pretty transparency and other visual effects package in the higher versions of Vista) disabled. So I opened the Performance Information & Tools feature in the Control Panel and selected Adjust Visual Effects. After turning off the vast majority (I left Use visual styles on windows and buttons because I just couldn't bear to look at the old grey XP-style taskbar any more), guess what? UAC is now lightning-fast and doesn't bother me at all.
I'll probably try re-enabling a few more settings and find the balance between speed and graphical sugar, but disabling most of the visual effects seems to have done the trick, and is already improving my Vista experience dramatically.
That said, it's slow as hell.
The UAC popup isn't bad on my monster desktop, which has a top-end Core 2 Duo, 4 GB of RAM, and a decent video card, but it takes FOREVER on my laptop - probably 3-5 seconds to black out the screen and pop up the prompt, and another 3-5 to black out the screen again and return me to what I was doing. This is unacceptable in 2008.
After reading a few unhelpful posts directing me to disable UAC completely, I found one that mentioned that it wasn't as slow with Aero (the pretty transparency and other visual effects package in the higher versions of Vista) disabled. So I opened the Performance Information & Tools feature in the Control Panel and selected Adjust Visual Effects. After turning off the vast majority (I left Use visual styles on windows and buttons because I just couldn't bear to look at the old grey XP-style taskbar any more), guess what? UAC is now lightning-fast and doesn't bother me at all.
I'll probably try re-enabling a few more settings and find the balance between speed and graphical sugar, but disabling most of the visual effects seems to have done the trick, and is already improving my Vista experience dramatically.
Tuesday, May 6, 2008
Python's subprocess doesn't like SmartFTP
Well, that was a frustrating afternoon. I was trying to automate the update process described in my previous post - an executable that uses SmartFTP's COM library to connect to an FTP server and download new files - by calling it from a Python script that would check the output and re-run the updater as necessary. I wanted to use the subprocess module, as I was advised by the Python docs that this was the New Cool Thing, and I wanted to use the environment variable functionality that it provided.
However, I consistently received the following error:
[20080506 19:05:00] SmartFTP FTP Library v1.5.8.21
[20080506 19:05:00] Resolving host name "ftp.******.com"
[20080506 19:05:00] Unable to resolve host name.
[20080506 19:05:00] 1
So I replaced the hostname with the IP address and got this error instead:
The requested service provider could not be loaded or initialized.
I found this phrase in the Microsoft Winsock documentation, at which point I had a mild aneurysm and went to work on something else for a while. I came back a little later to read that documentation, but it was unhelpful.
Finally I switched over to declaring the environment variables and calling the executable in a batch file and called that using os.system instead of subprocess... and it worked fine. So it appears that there's some incompatibility between this vendor app and/or SmartFTP's FTP library and Python's subprocess module. Guess I'll be using the tried and true os.system for now, because it's definitely not worth any more debugging time.
However, I consistently received the following error:
[20080506 19:05:00] SmartFTP FTP Library v1.5.8.21
[20080506 19:05:00] Resolving host name "ftp.******.com"
[20080506 19:05:00] Unable to resolve host name.
[20080506 19:05:00] 1
So I replaced the hostname with the IP address and got this error instead:
The requested service provider could not be loaded or initialized.
I found this phrase in the Microsoft Winsock documentation, at which point I had a mild aneurysm and went to work on something else for a while. I came back a little later to read that documentation, but it was unhelpful.
Finally I switched over to declaring the environment variables and calling the executable in a batch file and called that using os.system instead of subprocess... and it worked fine. So it appears that there's some incompatibility between this vendor app and/or SmartFTP's FTP library and Python's subprocess module. Guess I'll be using the tried and true os.system for now, because it's definitely not worth any more debugging time.
Friday, May 2, 2008
How to break your FTP client
Haven't posted in a while because I was in Russia for a few weeks checking out the smog, vodka, and beautiful women. Now I'm back, and I have a quick non-database item to relate.
Today I was working on scheduling the execution of some updater software from a small data vendor of ours. As it turns out, they have no spec or unified framework for their error handling and messages, so I had to work out what sort of errors could happen on my own. One thing the updater does is log on to the vendor's server via FTP and download new files. So naturally I wanted to prevent this to see what would happen.
The easiest way would have been to just unplug my network connection, but the app needs some files that live on the network, so that was out.
I tried to block the program with Windows Firewall, but we've got a bunch of Group Policy stuff applied there, which complicated things. Even when I unchecked my local firewall exception for the app, and then also the exception for FTP, the application connected to the vendor's FTP server without any trouble.
Next I went out and found a 3rd party app that could block ports. The one I settled on after a quick browse of some security sites was Ghost Personal Firewall. Simple, straightforward, free, quick installation - suited my needs perfectly. And it worked great. It took 2 minutes to download, install (no reboot needed), and configure a rule to block all traffic on port 21. This had the desired effect of breaking the app and producing an error log.
So consider this an unsolicited endorsement of Ghost's firewall. Served my purpose just fine, and it's going into my security toolkit for future app testing.
Today I was working on scheduling the execution of some updater software from a small data vendor of ours. As it turns out, they have no spec or unified framework for their error handling and messages, so I had to work out what sort of errors could happen on my own. One thing the updater does is log on to the vendor's server via FTP and download new files. So naturally I wanted to prevent this to see what would happen.
The easiest way would have been to just unplug my network connection, but the app needs some files that live on the network, so that was out.
I tried to block the program with Windows Firewall, but we've got a bunch of Group Policy stuff applied there, which complicated things. Even when I unchecked my local firewall exception for the app, and then also the exception for FTP, the application connected to the vendor's FTP server without any trouble.
Next I went out and found a 3rd party app that could block ports. The one I settled on after a quick browse of some security sites was Ghost Personal Firewall. Simple, straightforward, free, quick installation - suited my needs perfectly. And it worked great. It took 2 minutes to download, install (no reboot needed), and configure a rule to block all traffic on port 21. This had the desired effect of breaking the app and producing an error log.
So consider this an unsolicited endorsement of Ghost's firewall. Served my purpose just fine, and it's going into my security toolkit for future app testing.
Thursday, March 27, 2008
Returning rows from a stored procedure with pyodbc
I'll start with the executive summary for those of you short on time or who don't care about the background:
When executing multiple statements within a SQL Server stored procedure, including a SELECT statement that you expect to return rows to a rowset via pyodbc, it is necessary to SET NOCOUNT ON.
Backstory:
I ran into a new issue with pyodbc yesterday - an inability to parse rows returned by a SQL Server stored procedure. The proc in question was executing a number of queries, generating logging as rows to a table variable, and then returning the log via a select statement against the table variable.
However, when I executed the statement from a pyodbc connection, it didn't work.
This was a fairly complex proc that caused changes in the database when executed and I didn't want to run it repeatedly, so I mocked up "spTest" as follows:
create proc spTest as
select 'a' as msg
union all select 'b'
go
When executed from Python:
db = pyodbc.connect(CNXNSTRING, True)
rows = db.execute("exec spTest")
for row in rows:
print row
This returned rows. So I added a table variable:
create proc spTest2 as
declare @msgs table (msg varchar(255))
insert into @msgs
select 'a' as msg
union all select 'b'
select * from @msgs
go
This, being more similar to the actual proc, did not work. I changed a few things, tried a temp table instead of a table variable, etc., but didn't get any better results. Then my esteemed colleague Pijus asked if it was possible that pyodbc was reading some other channel of information from SQL that was obscuring the results. Aha!
SQL spits out rowcounts by default. I'm not sure where these turn up in ODBC world, but I know that they do get provided to the ODBC driver, and that does constitute an additional channel of information that could be confusing pyodbc. So I SET NOCOUNT ON, and voila, the final select returns results regardless of how many other operations occur within the procedure.
When executing multiple statements within a SQL Server stored procedure, including a SELECT statement that you expect to return rows to a rowset via pyodbc, it is necessary to SET NOCOUNT ON.
Backstory:
I ran into a new issue with pyodbc yesterday - an inability to parse rows returned by a SQL Server stored procedure. The proc in question was executing a number of queries, generating logging as rows to a table variable, and then returning the log via a select statement against the table variable.
However, when I executed the statement from a pyodbc connection, it didn't work.
This was a fairly complex proc that caused changes in the database when executed and I didn't want to run it repeatedly, so I mocked up "spTest" as follows:
create proc spTest as
select 'a' as msg
union all select 'b'
go
When executed from Python:
db = pyodbc.connect(CNXNSTRING, True)
rows = db.execute("exec spTest")
for row in rows:
print row
This returned rows. So I added a table variable:
create proc spTest2 as
declare @msgs table (msg varchar(255))
insert into @msgs
select 'a' as msg
union all select 'b'
select * from @msgs
go
This, being more similar to the actual proc, did not work. I changed a few things, tried a temp table instead of a table variable, etc., but didn't get any better results. Then my esteemed colleague Pijus asked if it was possible that pyodbc was reading some other channel of information from SQL that was obscuring the results. Aha!
SQL spits out rowcounts by default. I'm not sure where these turn up in ODBC world, but I know that they do get provided to the ODBC driver, and that does constitute an additional channel of information that could be confusing pyodbc. So I SET NOCOUNT ON, and voila, the final select returns results regardless of how many other operations occur within the procedure.
Wednesday, March 12, 2008
Case Sensitive GROUP BY
This is fairly trivial, but it took a few minutes to work out, so I figured I'd post it. Someone on my team needed to perform a case-sensitive GROUP BY operation on a table with a case-insensitive collation. I had performed case-sensitive SELECTs before by "casting" the field in question to an alternate collation, so I tried that, but couldn't get it to work at first. Of course, had I thought about it, I would have realized that the same operation needs to be applied in both the GROUP BY and the SELECT.
Ex:
create table foo
(bar varchar(20))
insert into foo select 'Banana'
insert into foo select 'banana'
insert into foo select 'Banana'
select * from foo
select
bar COLLATE SQL_Latin1_General_CP1_CS_AS
, count(*)
from foo
group by bar COLLATE SQL_Latin1_General_CP1_CS_AS
Alternately, one could use Microsoft's recommended method and convert the field to binary and then back. I haven't performance-tested the two methods, so I'm not sure which is faster. I leave that as an exercise for the reader. ;)
select convert(varchar(20),x.bar), x.ct
from
(select
convert(binary(20), bar) as bar
, count(*) as ct
from foo
group by convert(binary(20),bar)
) as x
Ex:
create table foo
(bar varchar(20))
insert into foo select 'Banana'
insert into foo select 'banana'
insert into foo select 'Banana'
select * from foo
select
bar COLLATE SQL_Latin1_General_CP1_CS_AS
, count(*)
from foo
group by bar COLLATE SQL_Latin1_General_CP1_CS_AS
Alternately, one could use Microsoft's recommended method and convert the field to binary and then back. I haven't performance-tested the two methods, so I'm not sure which is faster. I leave that as an exercise for the reader. ;)
select convert(varchar(20),x.bar), x.ct
from
(select
convert(binary(20), bar) as bar
, count(*) as ct
from foo
group by convert(binary(20),bar)
) as x
Monday, March 10, 2008
INSERT problems via pyodbc
This is really stupid, but I just wasted about an hour of dev time trying to figure out why my INSERT statements weren't working from a Python script using pyodbc even though SELECTs were fine. As it turns out, they were getting rolled back because I wasn't explicitly committing the transactions and hadn't set the AUTOCOMMIT option to true for the connection.
So if you happen to search for "pyodbc INSERT problems" (as I did), hopefully you'll stumble across this (as opposed to nothing, which is what I found) and slap yourself in the head (as I did).
So if you happen to search for "pyodbc INSERT problems" (as I did), hopefully you'll stumble across this (as opposed to nothing, which is what I found) and slap yourself in the head (as I did).
SQL Server CLR Remote Debugging
My CLR stored procs have matured to the point that they're being deployed, which is to say that the bugs are now insidious rather than blatant. It's a royal pain to make changes, deploy the project locally, run the post-deploy correction script to fix the decimal precision on everything (see previous post), debug any issues, and then do the whole deployment again to the dev server. It's much easier to just debug it straight on the server.
Fortunately, remote debugging is a straightforward process. Predictably, Microsoft's docs (here's one of many) on the subject are somewhat convoluted, although this msdn blog post helped.
All you really need to do is install Remote Debugging Monitor on the server and run it under the same login you use to connect to SQL. It comes with its own standalone installer on the Visual Studio CD, just look for the Remote Debugger directory and run the setup app found there. Then you can run it either manually or as a service.
Next, place a breakpoint in your code somewhere and deploy it to the server. I've had trouble with my test scripts when deploying/debugging all at once - basically, they hang without ever running - so what I've started doing is this:
1) Start without debugging (Ctrl-F5) to deploy to the remote server
2) Run my decimal parameter correction script
3) Attach to Process in Visual Studio to sqlservr.exe on the remote server
4) Execute the proc or UDF in a SQL Management Studio window
Then I can step through the code, look at locals, and generally debug to my heart's content.
Fortunately, remote debugging is a straightforward process. Predictably, Microsoft's docs (here's one of many) on the subject are somewhat convoluted, although this msdn blog post helped.
All you really need to do is install Remote Debugging Monitor on the server and run it under the same login you use to connect to SQL. It comes with its own standalone installer on the Visual Studio CD, just look for the Remote Debugger directory and run the setup app found there. Then you can run it either manually or as a service.
Next, place a breakpoint in your code somewhere and deploy it to the server. I've had trouble with my test scripts when deploying/debugging all at once - basically, they hang without ever running - so what I've started doing is this:
1) Start without debugging (Ctrl-F5) to deploy to the remote server
2) Run my decimal parameter correction script
3) Attach to Process in Visual Studio to sqlservr.exe on the remote server
4) Execute the proc or UDF in a SQL Management Studio window
Then I can step through the code, look at locals, and generally debug to my heart's content.
Friday, February 22, 2008
SqlDecimal truncation oddity
I've been working with all sorts of SQL CLR integration lately - User Defined Types (which are a bad idea), stored procs, and UDFs. In general, I'm pretty happy with the stored procedures, although I've run up against a number of irritating (but understandable) limitations, like the inability to dynamically load libraries and the requirement that only SQL data types be passed in and out of the CLR stored procs. But I haven't really broken any new ground, so I haven't written about it.
Today's issue is also not ground-breaking, but it is odd, so I thought I'd mention it. I wrote a function to convert a date into a decimal. Better that you not ask why. Here's the code:
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlDouble fnTimeSeriesCalcFracYrFromDateS(SqlDateTime inputDT)
{
DateTime dt = (DateTime)inputDT;
double temp = (dt.Year + (Math.Round(((double)dt.Month * (365 / 12) + (double)dt.Day) * 1000000 / 365) / 1000000));
SqlDecimal temp2 = (SqlDecimal)temp;
return temp2;
}
};
Obviously I could have dispensed with almost all of that by casting the data types within a single line, but I broke it out for debugging purposes.
Here's the funny part: when placing a breakpoint at the return statement, here are the values of the variables:
inputDT {1/2/2008 12:00:00 AM} System.Data.SqlTypes.SqlDateTime
dt {1/2/2008 12:00:00 AM} System.DateTime
temp 2008.087671 double
temp2 {2008.0876710000000} System.Data.SqlTypes.SqlDecimal
All as they should be. But the output of the function is 2008.
Why? I have no idea. I'm guessing it has something to do with the SqlDecimal declaration of the function, because when I changed it to SqlDouble, it returns 2008.087671 as it should. Anybody know why this is happening?
UPDATE: Figured it out. Visual Studio deploys the UDF without specifying a precision and scale, which causes the scale to be set to 0. One can circumvent this by dropping and re-creating the function manually within SQL Server and declaring the decimal data type with the desired precision and scale (in this case, (10,6)).
However, this is annoying because it turns a one-button deploy/debug process into a multi-step process, since one can't use the test script functionality in Visual Studio to run a script with multiple "GOs" to drop and re-create the function and then run it. The workaround I devised was to
1) Deploy the function to SQL via Visual Studio.
2) Drop and re-create the function manually in SQL Management Studio.
3) Set a breakpoint in VS.
4) Attach VS to the sqlservr.exe process.
5) Run the function. It should hit the breakpoint, allowing you to debug when it has the correct variable type settings.
But it would be nice to get back to where one press of F5 deployed and debugged the whole thing. Maybe I can figure out a way to set up a custom deploy script from VS...
UPDATE 2: When attempting to deploy the CLR functions after manually dropping them and re-creating them with the desired precision on the decimal return types, you get a Deploy error like the following:
The assembly module 'fnTimeSeriesCalcFracYrFromDateS' cannot be re-deployed because it was created outside of Visual Studio. Drop the module from the database before deploying the assembly.
To get around this, you can write a SQL script to drop the functions if they exist, save it into your project directory, and use the Pre-build event command line on the Build Events tab of the project properties to execute that drop script before each deploy. One less step per build!
Next I have to figure out how to get the post-build to execute the script to drop and recreate the functions with the proper precision.
Today's issue is also not ground-breaking, but it is odd, so I thought I'd mention it. I wrote a function to convert a date into a decimal. Better that you not ask why. Here's the code:
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlDouble fnTimeSeriesCalcFracYrFromDateS(SqlDateTime inputDT)
{
DateTime dt = (DateTime)inputDT;
double temp = (dt.Year + (Math.Round(((double)dt.Month * (365 / 12) + (double)dt.Day) * 1000000 / 365) / 1000000));
SqlDecimal temp2 = (SqlDecimal)temp;
return temp2;
}
};
Obviously I could have dispensed with almost all of that by casting the data types within a single line, but I broke it out for debugging purposes.
Here's the funny part: when placing a breakpoint at the return statement, here are the values of the variables:
inputDT {1/2/2008 12:00:00 AM} System.Data.SqlTypes.SqlDateTime
dt {1/2/2008 12:00:00 AM} System.DateTime
temp 2008.087671 double
temp2 {2008.0876710000000} System.Data.SqlTypes.SqlDecimal
All as they should be. But the output of the function is 2008.
Why? I have no idea. I'm guessing it has something to do with the SqlDecimal declaration of the function, because when I changed it to SqlDouble, it returns 2008.087671 as it should. Anybody know why this is happening?
UPDATE: Figured it out. Visual Studio deploys the UDF without specifying a precision and scale, which causes the scale to be set to 0. One can circumvent this by dropping and re-creating the function manually within SQL Server and declaring the decimal data type with the desired precision and scale (in this case, (10,6)).
However, this is annoying because it turns a one-button deploy/debug process into a multi-step process, since one can't use the test script functionality in Visual Studio to run a script with multiple "GOs" to drop and re-create the function and then run it. The workaround I devised was to
1) Deploy the function to SQL via Visual Studio.
2) Drop and re-create the function manually in SQL Management Studio.
3) Set a breakpoint in VS.
4) Attach VS to the sqlservr.exe process.
5) Run the function. It should hit the breakpoint, allowing you to debug when it has the correct variable type settings.
But it would be nice to get back to where one press of F5 deployed and debugged the whole thing. Maybe I can figure out a way to set up a custom deploy script from VS...
UPDATE 2: When attempting to deploy the CLR functions after manually dropping them and re-creating them with the desired precision on the decimal return types, you get a Deploy error like the following:
The assembly module 'fnTimeSeriesCalcFracYrFromDateS' cannot be re-deployed because it was created outside of Visual Studio. Drop the module from the database before deploying the assembly.
To get around this, you can write a SQL script to drop the functions if they exist, save it into your project directory, and use the Pre-build event command line on the Build Events tab of the project properties to execute that drop script before each deploy. One less step per build!
Next I have to figure out how to get the post-build to execute the script to drop and recreate the functions with the proper precision.
Monday, January 28, 2008
Arggh
I wrote this nice little piece of code to eliminate tons of redundant rows from a 70-million row table, tested it in a vacuum in Dev, put it in the Integration environment for 3 weeks... and had it blow up spectacularly when applied to Production this weekend because of triggers on the table that I hadn't accounted for. Stupid legacy code!
There's no real content to this story, I'm just venting. The only moral is TEST YOUR CODE.
There's no real content to this story, I'm just venting. The only moral is TEST YOUR CODE.
Subscribe to:
Posts (Atom)