This is barely relevant to anything, I just want to get this information out on the net.
If you are having problems installing a fresh copy of Windows XP on an IBM Thinkpad T20 because the windows installer / setup program crashes repeatedly in random places, this is the fix:
Remove the battery.
I don't know why it works, but I'm guessing something to do with either power management drivers or CPU speed-stepping. I spent probably 6 hours thrashing on this stupid thing before locating an obscure post on an MIT newsgroup. Hopefully this blog will be slightly easier to find if anyone else is ever doing this.
Thursday, March 29, 2007
Thursday, March 15, 2007
Too Much Information
I've noticed lately that my Google Reader inbox is more full than ever. It's not because of all the new feeds I'm adding - I've actually unsubscribed from a number of them. I don't have stats to back this up, but I believe it's because overall post volume on many blogs and news sites is increasing.
Fine. I like to stay informed, who doesn't?
Except that a lot of these posts are just for the sake of posting. When I read about disaster preparedness on Seeking Alpha and entertainment news (read: gossip) on The Register, something is wrong.
My friend Kevin Ho hates mainstream media. I disagree with him on most of his reasons, but he always points out that when the average person reads a newspaper article, he accepts that the facts and general position presented therein are accurate. Until he reads an article about a topic that he knows something about, and then he says, "What are these idiots talking about? They're missing the point entirely!"
Which is one of the reasons why I love blogs - it allows an expert in a certain subject to post about topics in an area in which he/she has extensive knowledge. And then I can aggregate the topics I care about in my RSS reader. No more amateurs writing about topics in which they have little background or understanding.
Unfortunately, many of these sites seem to be getting a big head about their traffic numbers and have started to assume that their readers live on their sites and go nowhere else, or else are attempting to squeeze more pageviews to generate those all-important ad dollars. At least, those are the possible rationales I've come up with for their explosions in posting, especially about topics outside their areas of expertise. Posts which are at best misguided, and at worst spam.
Even posts within a site's usual topical areas can be annoying if they're frivolous. For example, tech news outlets The Register and The Inquirer both post about 30-40 articles per day. Occasionally I'll click through to one with an interesting title, only to find that it's one paragraph long and contains no real information. Leave it out!
Mind you, I'm okay with a breadth of posts on personal blogs - the volume is low enough that ignoring the chaff doesn't take long, and some of it may even be interesting. And not all big sites are guilty of this posting diarrhea - Pitchfork only posts about music, Tom's Hardware about computer hardware, The Real Deal about real estate. But sites like Jalopnik and GigaOM, you're on notice. Keep up the crappy posts, and I'm dropping your feed.
(Yes, I realize that by posting this I'm guilty of the offense about which I'm complaining. I'm okay with the hypocrisy.)
Fine. I like to stay informed, who doesn't?
Except that a lot of these posts are just for the sake of posting. When I read about disaster preparedness on Seeking Alpha and entertainment news (read: gossip) on The Register, something is wrong.
My friend Kevin Ho hates mainstream media. I disagree with him on most of his reasons, but he always points out that when the average person reads a newspaper article, he accepts that the facts and general position presented therein are accurate. Until he reads an article about a topic that he knows something about, and then he says, "What are these idiots talking about? They're missing the point entirely!"
Which is one of the reasons why I love blogs - it allows an expert in a certain subject to post about topics in an area in which he/she has extensive knowledge. And then I can aggregate the topics I care about in my RSS reader. No more amateurs writing about topics in which they have little background or understanding.
Unfortunately, many of these sites seem to be getting a big head about their traffic numbers and have started to assume that their readers live on their sites and go nowhere else, or else are attempting to squeeze more pageviews to generate those all-important ad dollars. At least, those are the possible rationales I've come up with for their explosions in posting, especially about topics outside their areas of expertise. Posts which are at best misguided, and at worst spam.
Even posts within a site's usual topical areas can be annoying if they're frivolous. For example, tech news outlets The Register and The Inquirer both post about 30-40 articles per day. Occasionally I'll click through to one with an interesting title, only to find that it's one paragraph long and contains no real information. Leave it out!
Mind you, I'm okay with a breadth of posts on personal blogs - the volume is low enough that ignoring the chaff doesn't take long, and some of it may even be interesting. And not all big sites are guilty of this posting diarrhea - Pitchfork only posts about music, Tom's Hardware about computer hardware, The Real Deal about real estate. But sites like Jalopnik and GigaOM, you're on notice. Keep up the crappy posts, and I'm dropping your feed.
(Yes, I realize that by posting this I'm guilty of the offense about which I'm complaining. I'm okay with the hypocrisy.)
Wednesday, February 14, 2007
"Unable to perform a SETUSER to the requested username" error
This was a new one on me:

Backstory: We have an application that runs a SQL job every time a set of data is checked out. (I didn't design it.) Our development server was recently demolished by the SAN team while they were trying to add a new HBA, so it had to be rebuilt from scratch. After the rebuild, SQL was at version 8.0.2039 (SP4 w/ no hotfixes) and the job wouldn't run. It would spit out the above error each time, which was breaking the app.
This error looked like a permissions issue to me, so I started out by checking the user mapping. We'll call the login that runs the application "CORP\AppUser." This user was a member of dbowner in the database in the job step, so that wasn't the problem. Tried sp_start_job from Query Analyzer using those credentials, which worked, but still produced the error. Tried starting the job using my credentials instead, which produced the same error.
Then I changed the job owner to the same account that SQLAgent runs under, and the job worked. So it was definitely a permissions issue. I decided to check out the specific sequence of events underneath firing off a job, so I ran a Profiler trace and found this...
exec sp_setuserbylogin N'CORP\AppUser', 1
Hmm, what's that? It's not in BOL, and I couldn't find it in the master DB. But clearly SQL is trying to execute it, which might explain why the error it's returning is looking for user ''. I dug around a bit more and found some code to add it back into master.
exec sp_addextendedproc N'sp_setuserbylogin', N'(server internal)'
Voila! As soon as I ran this code, the job worked like a charm. Apparently a botched SP3 or 4 install can miss this proc, which is what probably happened here. So if you come across this error, make sure you've got sp_setuserbylogin properly installed.

Backstory: We have an application that runs a SQL job every time a set of data is checked out. (I didn't design it.) Our development server was recently demolished by the SAN team while they were trying to add a new HBA, so it had to be rebuilt from scratch. After the rebuild, SQL was at version 8.0.2039 (SP4 w/ no hotfixes) and the job wouldn't run. It would spit out the above error each time, which was breaking the app.
This error looked like a permissions issue to me, so I started out by checking the user mapping. We'll call the login that runs the application "CORP\AppUser." This user was a member of dbowner in the database in the job step, so that wasn't the problem. Tried sp_start_job from Query Analyzer using those credentials, which worked, but still produced the error. Tried starting the job using my credentials instead, which produced the same error.
Then I changed the job owner to the same account that SQLAgent runs under, and the job worked. So it was definitely a permissions issue. I decided to check out the specific sequence of events underneath firing off a job, so I ran a Profiler trace and found this...
exec sp_setuserbylogin N'CORP\AppUser', 1
Hmm, what's that? It's not in BOL, and I couldn't find it in the master DB. But clearly SQL is trying to execute it, which might explain why the error it's returning is looking for user ''. I dug around a bit more and found some code to add it back into master.
exec sp_addextendedproc N'sp_setuserbylogin', N'(server internal)'
Voila! As soon as I ran this code, the job worked like a charm. Apparently a botched SP3 or 4 install can miss this proc, which is what probably happened here. So if you come across this error, make sure you've got sp_setuserbylogin properly installed.
Wednesday, January 31, 2007
Stupid general-purpose connection errors
Had to debug a stupid error today being thrown by the VBscript we use to deploy DTS packages. Here's the text of the error:
[DBNETLIB][ConnectionRead (WrapperRead()).]
Pretty helpful, huh?
Although it wasn't difficult to debug after I got access to the script source. Here's the line that was producing the error:
Set oPackageSQLServer = oApplication.GetPackageSQLServer(sDestServer, sUser , sPwd , 0)
I tried connecting to the server using the same credentials, which broke with another unhelpful error. Then I logged into the server directly and tried logging in there, where it informed me that the default database for that user was unavailable. Aha! That DB was in the middle of a restore. So I changed the default database and was able to transfer packages.
I'm posting this so that somebody trying to track down this error with the PackageSQLServer object might land here and see this message:
Check your login credentials!
[DBNETLIB][ConnectionRead (WrapperRead()).]
Pretty helpful, huh?
Although it wasn't difficult to debug after I got access to the script source. Here's the line that was producing the error:
Set oPackageSQLServer = oApplication.GetPackageSQLServer(sDestServer, sUser , sPwd , 0)
I tried connecting to the server using the same credentials, which broke with another unhelpful error. Then I logged into the server directly and tried logging in there, where it informed me that the default database for that user was unavailable. Aha! That DB was in the middle of a restore. So I changed the default database and was able to transfer packages.
I'm posting this so that somebody trying to track down this error with the PackageSQLServer object might land here and see this message:
Check your login credentials!
Tuesday, January 30, 2007
Blocking Chain script
I had a need to follow some quickly changing blocking chains today, and couldn't find any simple blocking chain scripts that I liked, so I wrote one. It's not the prettiest method, but it's simple, easy to modify, and doesn't rely on lots of hard-to-debug dynamic SQL.
The next updates I'll probably make will be to display only the top-level blockers rather than all blocking chains, and to get rid of the 0s at the end of each blocking chain line.
Here's the SQL:
Sample output:

The next updates I'll probably make will be to display only the top-level blockers rather than all blocking chains, and to get rid of the 0s at the end of each blocking chain line.
Here's the SQL:
if object_id('tempdb..#blockers0') is not null
drop table #blockingchain
create table #blockingchain
(
blockingchain varchar(255)
)
insert into #blockingchain
select cast(spid as varchar(5)) + ' -> ' + cast(blocked as varchar(5))
from master..sysprocesses
where blocked <> 0
while exists (select 1 from #blockingchain where cast((substring(right(blockingchain, 5), 1 + charindex('>', right(blockingchain, 5)), 5)) as smallint) <> 0)
begin
update bc set blockingchain = blockingchain + ' -> ' + cast(sp.blocked as varchar(5))
from #blockingchain bc
inner join master..sysprocesses sp
on cast((substring(right(bc.blockingchain, 5), 1 + charindex('>', right(bc.blockingchain, 5)), 5)) as smallint) = sp.spid
end
select * from #blockingchain
order by len(blockingchain) asc,
substring(blockingchain, 1, charindex('-', blockingchain)) asc
Sample output:

Wednesday, January 17, 2007
Changing the Domain for a SQL 2005 Cluster
NOTE: It looks like my old DBAIQ blog may be down for the count due to Blogger issues, and I didn't want to lose my post on changing the domain for a SQL 2005 cluster, so I retrieved it from Google's search cache, and am reprinting it here. Ironic that Google was both the cause of its destruction (taking over Blogger and breaking our team blog) and its recovery (search cache).
We're moving our Dev environment to a new domain for some unfathomable corporate reason, and it's going to be a major headache. Among our 20+ SQL Servers in the environment, we've got a few SQL 2005 clusters. According to Microsoft, we can't move them without uninstalling SQL.
http://support.microsoft.com/kb/915846/en-us
Needless to say, this would add more pain to the migration process. It wouldn't be the end of the world, but this is weekend work, and uninstalling and re-installing a couple active/active SQL clusters is just the thing to turn 1 day of work into 2+.
However, I think they're wrong.
I built two virtual machines on VMWare Server, added them to a cluster (see Repeatable Read for instructions on creating shared disks in VMWare) on our current domain, and created some databases. Verified failover capability and connectivity.
Then I moved both nodes to the new domain using the following steps:
1) Take all cluster resources offline (except the quorum, which cannot be taken offline)
2) Stop the cluster service on both nodes
3) Change the cluster service startup type to Manual
4) Change the domain of each machine to the new domain and reboot
5) After reboot, on each machine, change the cluster and SQL service accounts to accounts in the new domain
6) Run gpedit.msc or otherwise access Local Security Policy Settings (see below), and grant the following rights:
Cluster Service Account
Act as part of the operating system
Adjust memory quotas for a process
Debug programs
Increase scheduling priority
Manage auditing and security log
Restore files and directories
SQL Service Account
Adjust memory quotas for a process
Lock pages in memory
Log on as a batch job
Log on as a service
Replace a process level token
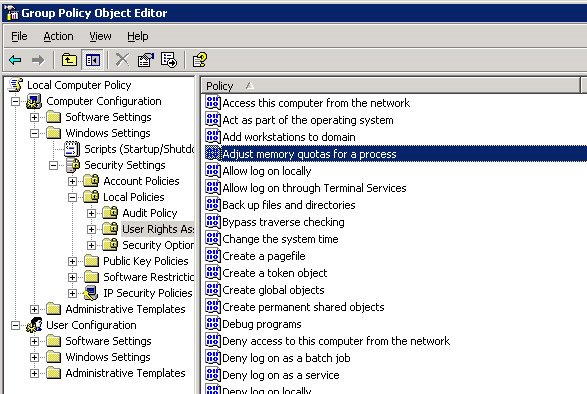
7) Add the cluster and SQL service accounts to the local Adminstrators group. NOTE: This should not be necessary for SQL, and I will update this with the minimum required permissions as soon as I sort them out. It is necessary for the cluster account, however.
8) Start the cluster service on both machines
9) Bring cluster resources online
10) Go enjoy the rest of your weekend
If you missed some permissions, the cluster service will likely fail to start with an error 7023 or 1321, and will helpfully output an error in the system log with eventId 1234 that contains a list of the necessary user rights that still need to be assigned. Now that's error reporting!
Comprehensive testing is still pending, but the preliminary results look good. After this process, SQL Server comes online on my test cluster, as do SQL Agent and Fulltext. I don't have any machines on the new domain with SQL Management Studio installed, but I could connect to SQL using osql directly on one of the cluster nodes. If anyone out there has any different experiences or comments, I'd love to hear them.
UPDATE:
My previous post left out one small but significant detail: the domain groups under which the SQL Server service accounts run. When one installs SQL 2005 on a cluster, the setup program requires domain groups to be entered for each service account. So for example:
SQL Server service account: OLDDOMAIN\SQLService
SQL Agent service account: OLDDOMAIN\SQLAgentService
SQL Browser service account: OLDDOMAIN\SQLBrowserService
Domain groups:
OLDDOMAIN\SQLServiceGroup
OLDDOMAIN\SQLAgentServiceGroup
OLDDOMAIN\FullTextGroup
Then it comes time to move your cluster, and you've followed my steps above or done your own hacking, and you've changed the service accounts to NEWDOMAIN\SQLService and so on. But the domain groups remain the same. Your cluster will come online and fail over and operate fine, but you won't be able to change it.
This was made evident when I tried to add a node to an existing cluster after moving it to a new domain. It gave me a message like "Cannot add NEWDOMAIN\SQLService to OLDDOMAIN\SQLServiceGroup." Arrgh. Microsoft had already claimed that this was not supported, so I suppose I shouldn't have been surprised.
So I started searching for the reference to OLDDOMAIN\SQLServiceGroup. And couldn't find it. Not in a config file, or a system table (I know, that was dumb, but I was desperate), or the registry, where I expected to find it. Eventually, I started combing the registry key by key within the SQL hives and came across this in HKLM\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL.1\Setup...
(okay, I tried to upload another image here to illustrate, but Blogger hates me, so screw it.)
The keys AGTGroup, FTSGroup, and SQLGroup contain the SIDs for whatever OLDDOMAIN groups you set up when installing SQL. Find the SIDs for your new domain groups (the VBScript below is how I did it), enter those in place of the old ones, restart SQL, and your cluster is moved. You should now be able to add or remove nodes, install hotfixes, etc. You'll need to update the SIDs for each SQL installation (MSSQL.2, MSSQL.3, etc.)
As with any unsupported operation, your mileage may vary, but let me know if you have a different experience with this or you run into additional problems.
We're moving our Dev environment to a new domain for some unfathomable corporate reason, and it's going to be a major headache. Among our 20+ SQL Servers in the environment, we've got a few SQL 2005 clusters. According to Microsoft, we can't move them without uninstalling SQL.
http://support.microsoft.com/kb/915846/en-us
Needless to say, this would add more pain to the migration process. It wouldn't be the end of the world, but this is weekend work, and uninstalling and re-installing a couple active/active SQL clusters is just the thing to turn 1 day of work into 2+.
However, I think they're wrong.
I built two virtual machines on VMWare Server, added them to a cluster (see Repeatable Read for instructions on creating shared disks in VMWare) on our current domain, and created some databases. Verified failover capability and connectivity.
Then I moved both nodes to the new domain using the following steps:
1) Take all cluster resources offline (except the quorum, which cannot be taken offline)
2) Stop the cluster service on both nodes
3) Change the cluster service startup type to Manual
4) Change the domain of each machine to the new domain and reboot
5) After reboot, on each machine, change the cluster and SQL service accounts to accounts in the new domain
6) Run gpedit.msc or otherwise access Local Security Policy Settings (see below), and grant the following rights:
Cluster Service Account
Act as part of the operating system
Adjust memory quotas for a process
Debug programs
Increase scheduling priority
Manage auditing and security log
Restore files and directories
SQL Service Account
Adjust memory quotas for a process
Lock pages in memory
Log on as a batch job
Log on as a service
Replace a process level token
7) Add the cluster and SQL service accounts to the local Adminstrators group. NOTE: This should not be necessary for SQL, and I will update this with the minimum required permissions as soon as I sort them out. It is necessary for the cluster account, however.
8) Start the cluster service on both machines
9) Bring cluster resources online
10) Go enjoy the rest of your weekend
If you missed some permissions, the cluster service will likely fail to start with an error 7023 or 1321, and will helpfully output an error in the system log with eventId 1234 that contains a list of the necessary user rights that still need to be assigned. Now that's error reporting!
Comprehensive testing is still pending, but the preliminary results look good. After this process, SQL Server comes online on my test cluster, as do SQL Agent and Fulltext. I don't have any machines on the new domain with SQL Management Studio installed, but I could connect to SQL using osql directly on one of the cluster nodes. If anyone out there has any different experiences or comments, I'd love to hear them.
UPDATE:
My previous post left out one small but significant detail: the domain groups under which the SQL Server service accounts run. When one installs SQL 2005 on a cluster, the setup program requires domain groups to be entered for each service account. So for example:
SQL Server service account: OLDDOMAIN\SQLService
SQL Agent service account: OLDDOMAIN\SQLAgentService
SQL Browser service account: OLDDOMAIN\SQLBrowserService
Domain groups:
OLDDOMAIN\SQLServiceGroup
OLDDOMAIN\SQLAgentServiceGroup
OLDDOMAIN\FullTextGroup
Then it comes time to move your cluster, and you've followed my steps above or done your own hacking, and you've changed the service accounts to NEWDOMAIN\SQLService and so on. But the domain groups remain the same. Your cluster will come online and fail over and operate fine, but you won't be able to change it.
This was made evident when I tried to add a node to an existing cluster after moving it to a new domain. It gave me a message like "Cannot add NEWDOMAIN\SQLService to OLDDOMAIN\SQLServiceGroup." Arrgh. Microsoft had already claimed that this was not supported, so I suppose I shouldn't have been surprised.
So I started searching for the reference to OLDDOMAIN\SQLServiceGroup. And couldn't find it. Not in a config file, or a system table (I know, that was dumb, but I was desperate), or the registry, where I expected to find it. Eventually, I started combing the registry key by key within the SQL hives and came across this in HKLM\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL.1\Setup...
(okay, I tried to upload another image here to illustrate, but Blogger hates me, so screw it.)
The keys AGTGroup, FTSGroup, and SQLGroup contain the SIDs for whatever OLDDOMAIN groups you set up when installing SQL. Find the SIDs for your new domain groups (the VBScript below is how I did it), enter those in place of the old ones, restart SQL, and your cluster is moved. You should now be able to add or remove nodes, install hotfixes, etc. You'll need to update the SIDs for each SQL installation (MSSQL.2, MSSQL.3, etc.)
As with any unsupported operation, your mileage may vary, but let me know if you have a different experience with this or you run into additional problems.
SQL Litespeed works better when unregistered
I recently set up a new DR server that had recently been built from scratch, and the DBAs who set it up didn't have a product key for SQL Litespeed, which we use to backup all of our databases. If you don't know about Litespeed, go check it out, it's handy. So the DBAs set it up using a trial version of the software.
After that, I set up an automatic restore process on the DR servers, but it was taking forever. A backup that would restore in 4-5 hours on the hardware-inferior DR QA server would take 18-20 hours on the Production DR server. This gave us a potentially long recovery time and precluded using the DR machine for reporting or other tasks. I ran a series of diagnostics against the server, and eventually even involved the SAN team, but everything looked fine - disk queues and CPU usage were low, the drives were clearly capable of much higher IOs, etc.
Then one day, the restores sped up. Not by a little bit, but by 10x - from 18 hours to 85-90 minutes. Hey, cool. Except I didn't know what had happened. But it was working and I had other stuff to do, so I left it alone.
A week later, I attempted to take a backup of a DB on that server and got an error message informing me that SQL Litespeed's trial period had expired. I checked that the backups were still restoring, which they were, and sent another request for a Litespeed license.
The request came through a few weeks later, and on the day that Litespeed was officially registered, the backups started taking 18 hours again. Bizarre? Yeah. I'm tempted to uninstall the licensed version and run it in trial mode again unless Quest can give me a good explanation as to why this is happening and how to fix it.
Here's some sample output from Litespeed on our server, with sensitive data redacted. Emphasis is mine.
Executed as user: [user]. Warning: Null value is eliminated by an aggregate or other SET operation. [SQLSTATE 01003] (Message 8153) Processed 29616984 pages for database '[dbname]', file '[dbname]_Data' on file 1. Processed 26037664 pages for database '[dbname]', file '[dbname]_Data2' on file 1. Processed 23631992 pages for database '[dbname]', file '[dbname]_Data3' on file 1. Processed 16 pages for database '[dbname]', file '[dbname]_Log' on file 1. RESTORE DATABASE successfully processed 79286656 pages in 5051.204 seconds (128.586 MB/sec). CPU Seconds: 8190.55 Environment: Intel(R) Xeon(TM) MP CPU 3.00GHz CPUs: 8 logical, 8 cores, 8 physical packages. [SQLSTATE 01000] (Message 1). The step succeeded.
Executed as user: [user]. Warning: Null value is eliminated by an aggregate or other SET operation. [SQLSTATE 01003] (Message 8153) Processed 29616984 pages for database '[dbname]', file '[dbname]_Data' on file 1. Processed 26037664 pages for database '[dbname]', file '[dbname]_Data2' on file 1. Processed 23631992 pages for database '[dbname]', file '[dbname]_Data3' on file 1. Processed 16 pages for database '[dbname]', file '[dbname]_Log' on file 1. RESTORE DATABASE successfully processed 79286656 pages in 69992.264 seconds (9.279 MB/sec). CPU Seconds: 7422.05 Environment: Intel(R) Xeon(TM) MP CPU 3.00GHz CPUs: 8 logical, 8 cores, 8 physical packages. [SQLSTATE 01000] (Message 1). The step succeeded.
After that, I set up an automatic restore process on the DR servers, but it was taking forever. A backup that would restore in 4-5 hours on the hardware-inferior DR QA server would take 18-20 hours on the Production DR server. This gave us a potentially long recovery time and precluded using the DR machine for reporting or other tasks. I ran a series of diagnostics against the server, and eventually even involved the SAN team, but everything looked fine - disk queues and CPU usage were low, the drives were clearly capable of much higher IOs, etc.
Then one day, the restores sped up. Not by a little bit, but by 10x - from 18 hours to 85-90 minutes. Hey, cool. Except I didn't know what had happened. But it was working and I had other stuff to do, so I left it alone.
A week later, I attempted to take a backup of a DB on that server and got an error message informing me that SQL Litespeed's trial period had expired. I checked that the backups were still restoring, which they were, and sent another request for a Litespeed license.
The request came through a few weeks later, and on the day that Litespeed was officially registered, the backups started taking 18 hours again. Bizarre? Yeah. I'm tempted to uninstall the licensed version and run it in trial mode again unless Quest can give me a good explanation as to why this is happening and how to fix it.
Here's some sample output from Litespeed on our server, with sensitive data redacted. Emphasis is mine.
Executed as user: [user]. Warning: Null value is eliminated by an aggregate or other SET operation. [SQLSTATE 01003] (Message 8153) Processed 29616984 pages for database '[dbname]', file '[dbname]_Data' on file 1. Processed 26037664 pages for database '[dbname]', file '[dbname]_Data2' on file 1. Processed 23631992 pages for database '[dbname]', file '[dbname]_Data3' on file 1. Processed 16 pages for database '[dbname]', file '[dbname]_Log' on file 1. RESTORE DATABASE successfully processed 79286656 pages in 5051.204 seconds (128.586 MB/sec). CPU Seconds: 8190.55 Environment: Intel(R) Xeon(TM) MP CPU 3.00GHz CPUs: 8 logical, 8 cores, 8 physical packages. [SQLSTATE 01000] (Message 1). The step succeeded.
Executed as user: [user]. Warning: Null value is eliminated by an aggregate or other SET operation. [SQLSTATE 01003] (Message 8153) Processed 29616984 pages for database '[dbname]', file '[dbname]_Data' on file 1. Processed 26037664 pages for database '[dbname]', file '[dbname]_Data2' on file 1. Processed 23631992 pages for database '[dbname]', file '[dbname]_Data3' on file 1. Processed 16 pages for database '[dbname]', file '[dbname]_Log' on file 1. RESTORE DATABASE successfully processed 79286656 pages in 69992.264 seconds (9.279 MB/sec). CPU Seconds: 7422.05 Environment: Intel(R) Xeon(TM) MP CPU 3.00GHz CPUs: 8 logical, 8 cores, 8 physical packages. [SQLSTATE 01000] (Message 1). The step succeeded.
Subscribe to:
Posts (Atom)